
저는 한글날에 문득 언어뭉치라 볼 수 있는 LLM중에서 에이닷에 탑제된 A.X에 대한 궁금증이 생겼어요!
“멀티 LLM 에이전트”를 통해서 알아보도록 할게요! 특히 검색에 특화된 Perplexity를 먼저 활용했어요.
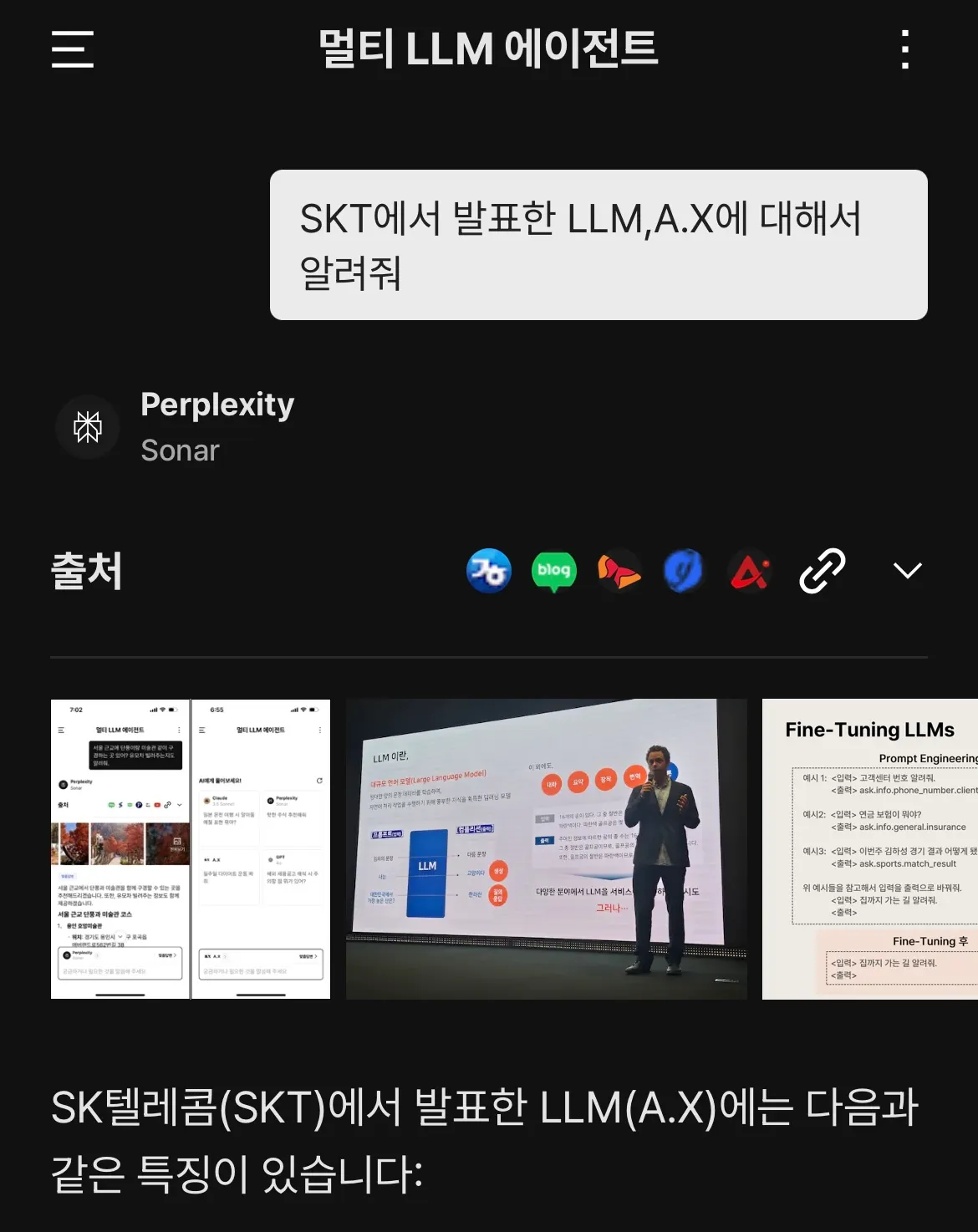



GPT에서도 적용된 RLHF 과정을 거쳤구나! 사용하면서 정말 다양한 한국어 학습을 했다는걸 경험했어요. 성심당의 빵 종류도 다 알고있는 너… 비범한건 확실하더라! 한국어 데이터를 얼마나 학습했는지 문득 궁금해졌어요!
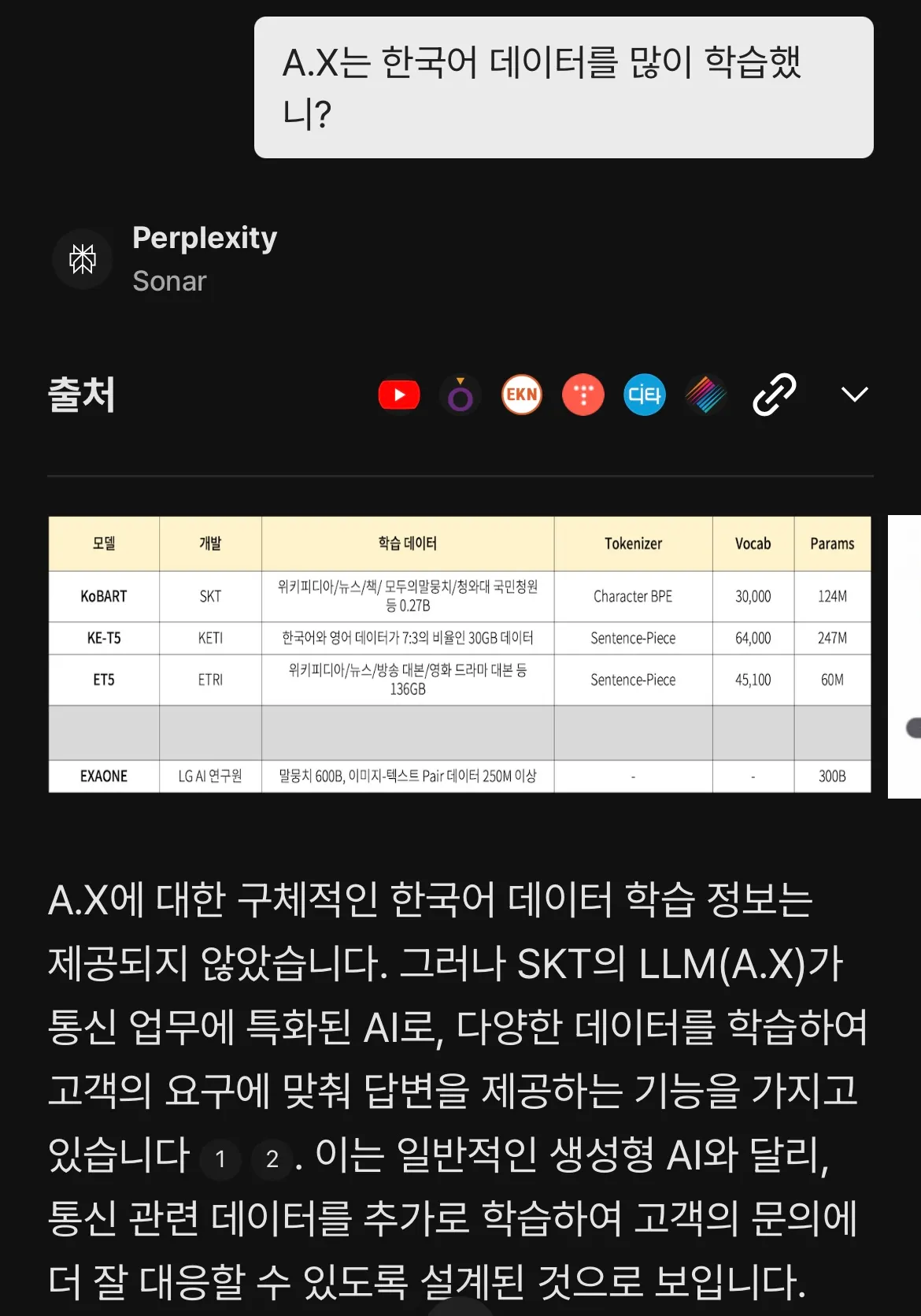

KoBART를 SKT에서 만들걸 보니 동일한 데이터와 추가적인 데이터를 이용하지 않았을까 추측되는데, 우리나라만의 데이터가 들어간 LLM이구나!
그럼 이제 너랑 한글날에 대한 고찰을 해보겠어!
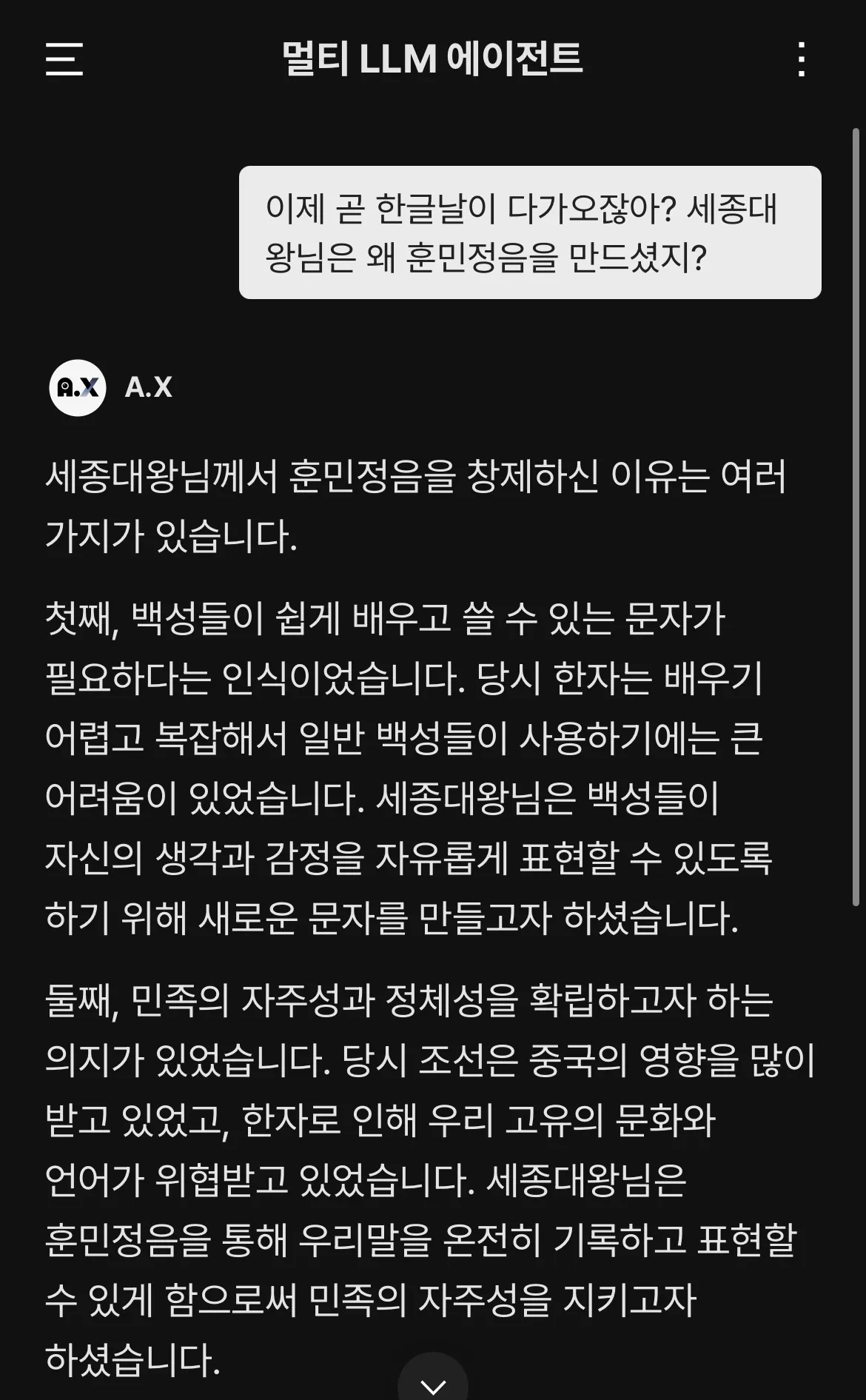
언어는 문자, 의사소통의 도구로 그치지 않고, 한 나라의 자주성과 정체성을 형성한다니!
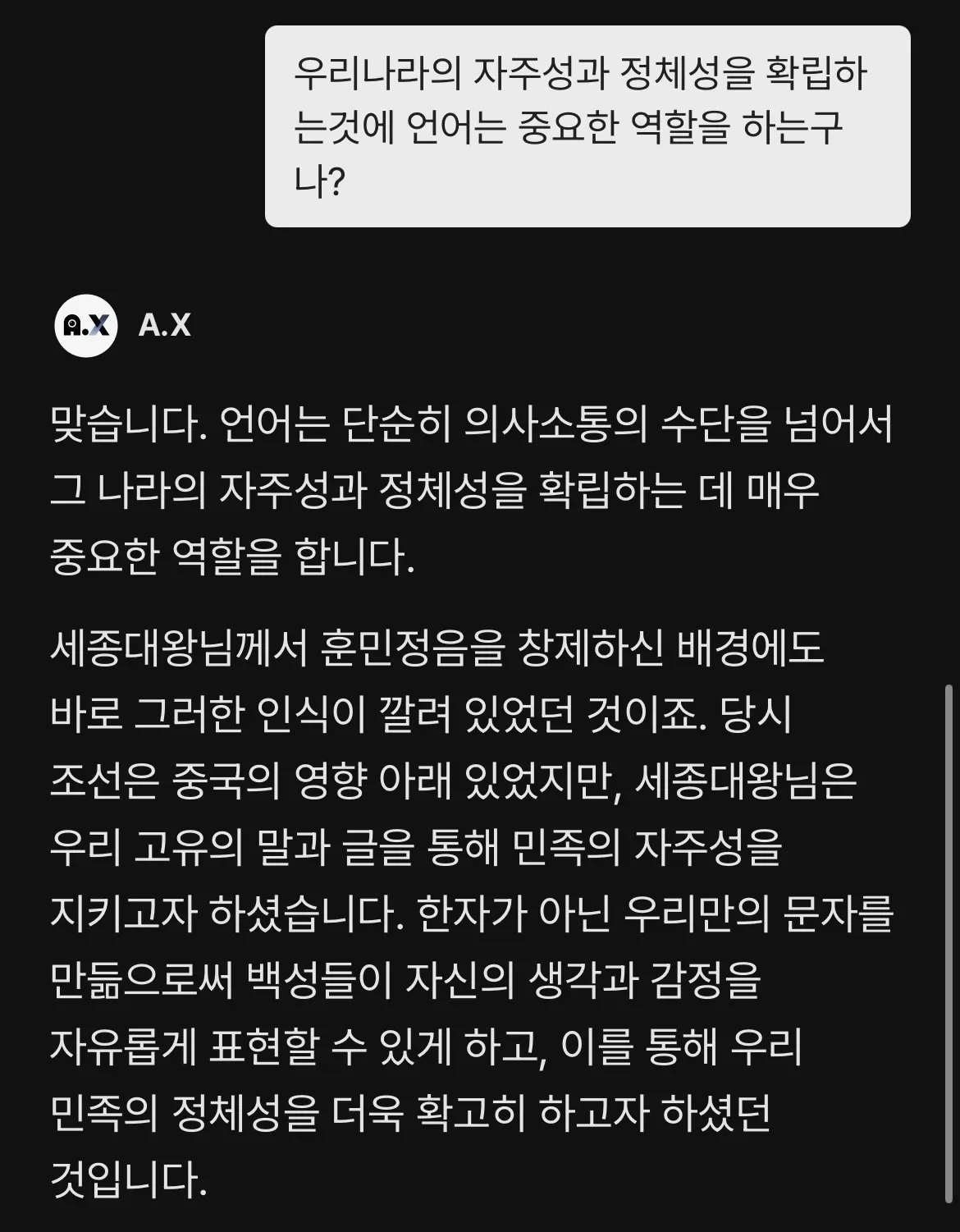

거의 모든 데이터가 영어 기반인 해외 LLM의 범람속에서, 우리말 데이터를 더 집중해 담은 LLM A.X은 대단한데?!


우리말 LLM인 SKT의 A.X, 꼭 응원할게 :)


(이쯤되면 개발자분이 빡세게 담아두신거 같은데…?!)
우리나라의 언어모델을 구축해 LLM의 자주성을 지키고, 모두가 쉽게 사용할 수 있는 A.X도 우리 민족의 자주성과 정체성을 지키고, 모두가 쉽게 배울 수 있는 훈민정음을 만든 세종대왕 덕분에 존재할 수 있다는 사실을 잊어버리면 안되겠네! 오늘 하루만큼이라도 한글의 소중함을 반드시 느껴야겠어!